When a robot sees the same scene twice, it shouldn’t always do the same thing — sometimes pushing left is just as good as pushing right. This is the central challenge of behavior cloning: expert demonstrations contain multiple valid modes of behavior, and naive imitation averages over them, producing actions that belong to none. The dominant solutions either discretize the action space or denoise through diffusion, each with its own overhead: codebooks, noise schedules, multi-step inference. But what if you could just tokenize actions and predict the next one, the same way language models already handle multimodal text? This post puts all three head-to-head on Push-T — and asks whether the simplest of them can keep up.
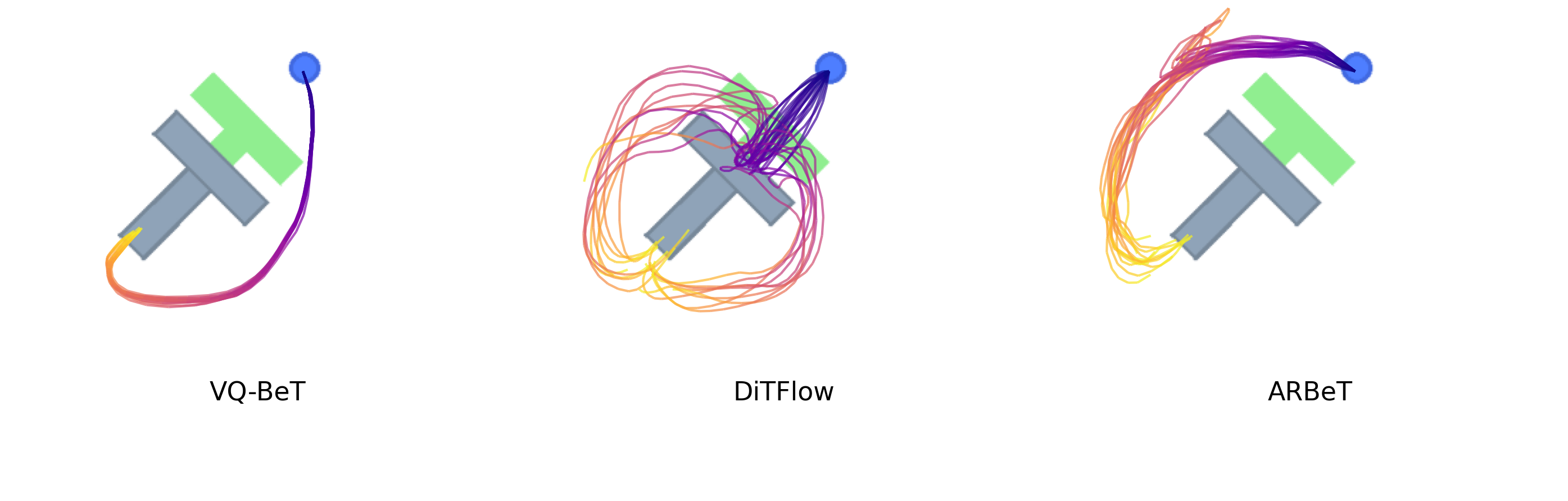
Setup
The task is Push-T: a 2D environment where the agent must push a T-shaped block to a target pose by outputting target positions. Each policy conditions on recent timesteps — previous actions, the agent’s position, and a 96×96 environment image — to produce a chunk of future actions. Images are encoded by a ResNet into a compact embedding, and a transformer fuses both streams to output the action representation.
All three are implemented in the LeRobot framework, but at increasing levels of customization. VQ-BeT ships as a built-in policy. DiTFlow adapts an existing open-source plugin. ARBeT is written from scratch: custom tokenizer, dataset, and policy. Code is available here.
Training hyperparameters (learning rate, batch size, optimizer settings, warmup schedule) are adapted from LeRobot’s published VQ-BeT and Diffusion Policy checkpoints for Push-T, and held constant across all three policies to isolate the effect of the action representation.
Paradigm 1: Discretize It — VQ-BeT
Theory
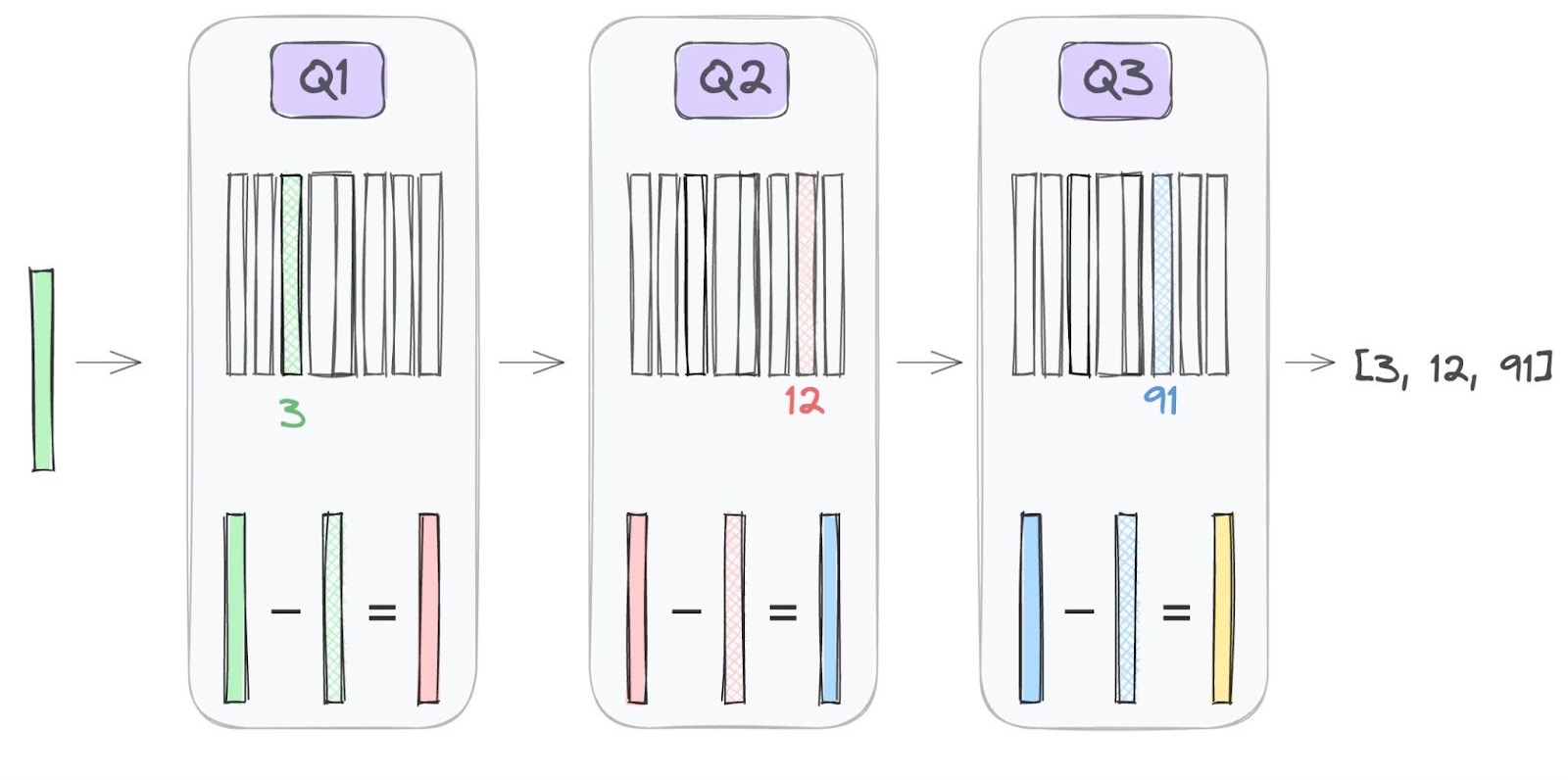
Each quantizer snaps the input to its nearest codebook vector and passes the residual to the next stage, progressively refining the approximation. Figure from AssemblyAI.
A natural way to handle multimodal actions is to discretize them. The behavior transformer (BeT) learns bins via k-means, then trains a transformer to predict a categorical distribution over them. This lets the model assign probability to “push left” and “push right” without averaging them. VQ-BeT improves on this by replacing fixed k-means with a learned VQ-VAE codebook: an encoder snaps continuous actions to their nearest codebook vectors, and a decoder learns to reconstruct the originals, so the codebook ends up capturing the structure of the action space.
The prediction model is a causal GPT whose input interleaves observation tokens with learned action query tokens. For Push-T with five observation steps, the sequence looks like [img₁, state₁, AQ₁, img₂, state₂, AQ₂, …, img₅, state₅, AQ₅, AQ₆, AQ₇] — five observation-aligned triplets followed by two extra future action queries. Each action query can only attend to tokens at or before its position, so it learns to predict codebook indices for a chunk of future timesteps from preceding context. During rollout, only AQ₅ — the one aligned with the current observation — is decoded into the next action chunk.
Snapping to discrete codes loses fine-grained detail. VQ-BeT recovers it with residual quantization (a second, smaller codebook encodes the error left by the first) plus a continuous offset head that corrects whatever remains. At inference, each action query autoregressively predicts its codebook indices (primary, then residual), sums the corresponding vectors, and adds the offset to produce a full-fidelity continuous action.
Implementation
VQ-BeT ships as a built-in policy in LeRobot, so I trained it on Push-T with a single CLI command. This makes it a convenient baseline against the two custom implementations that follow.
python -m lerobot.scripts.lerobot_train \
--dataset.repo_id=lerobot/pusht \
--policy.type=vqbetParadigm 2: Denoise It — DiTFlow
Theory
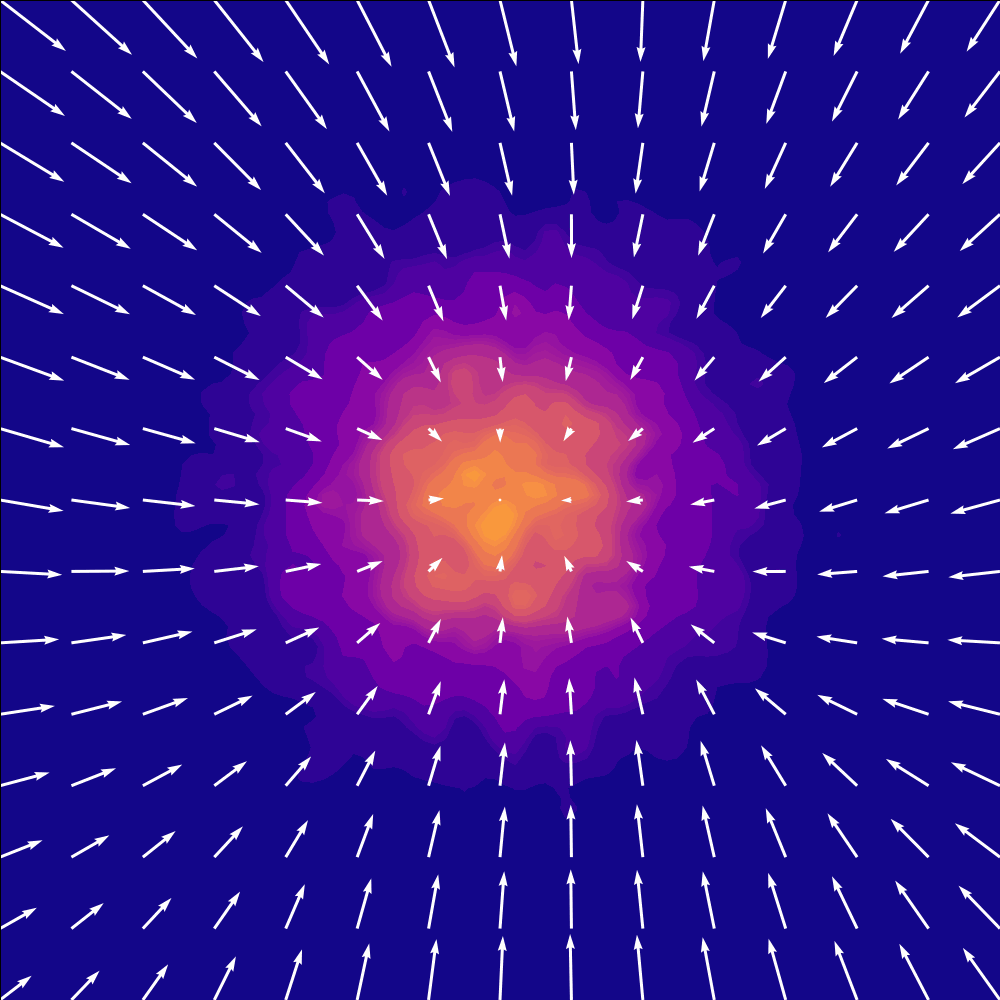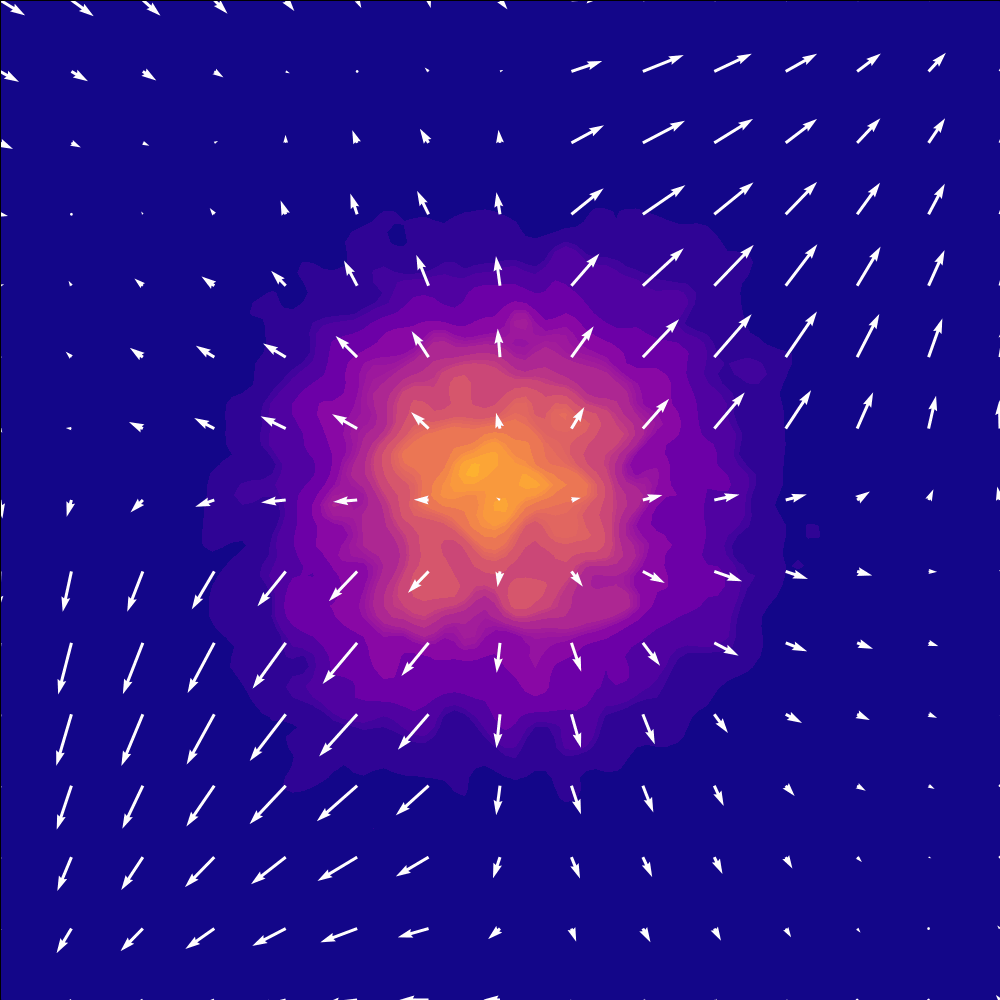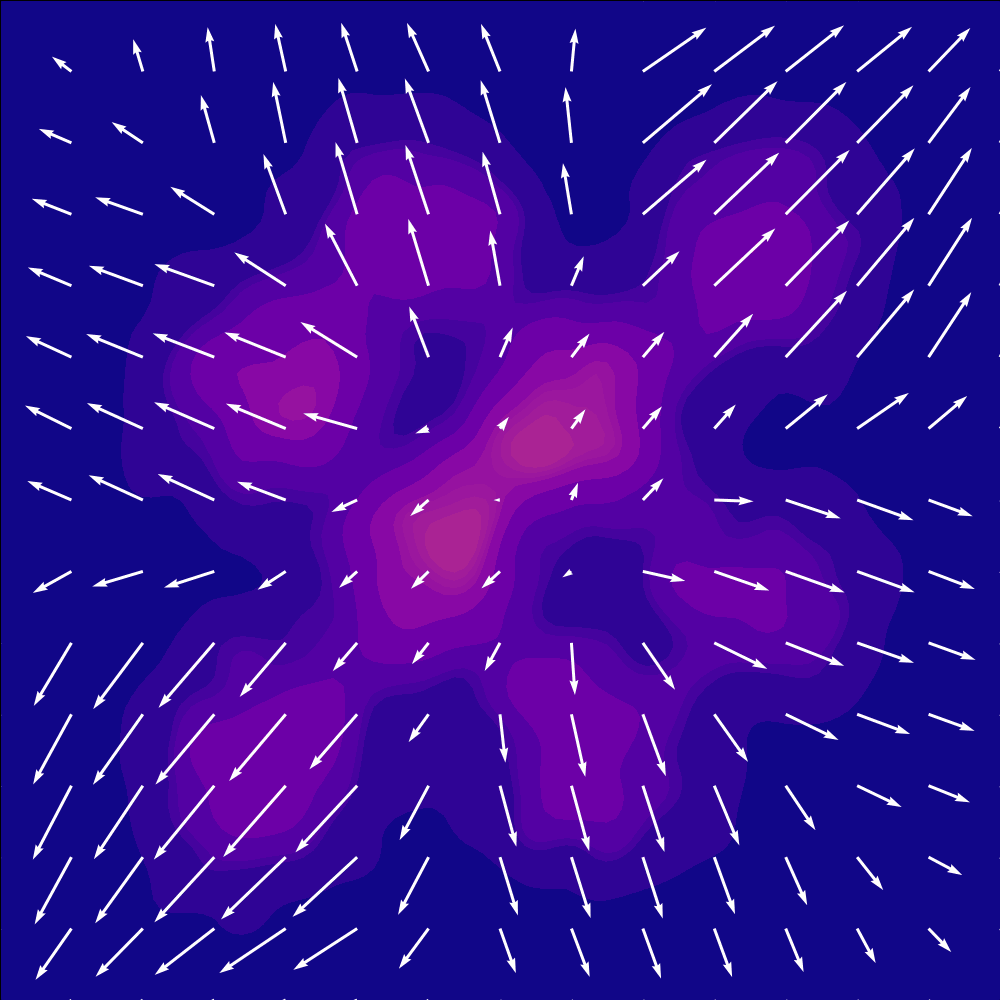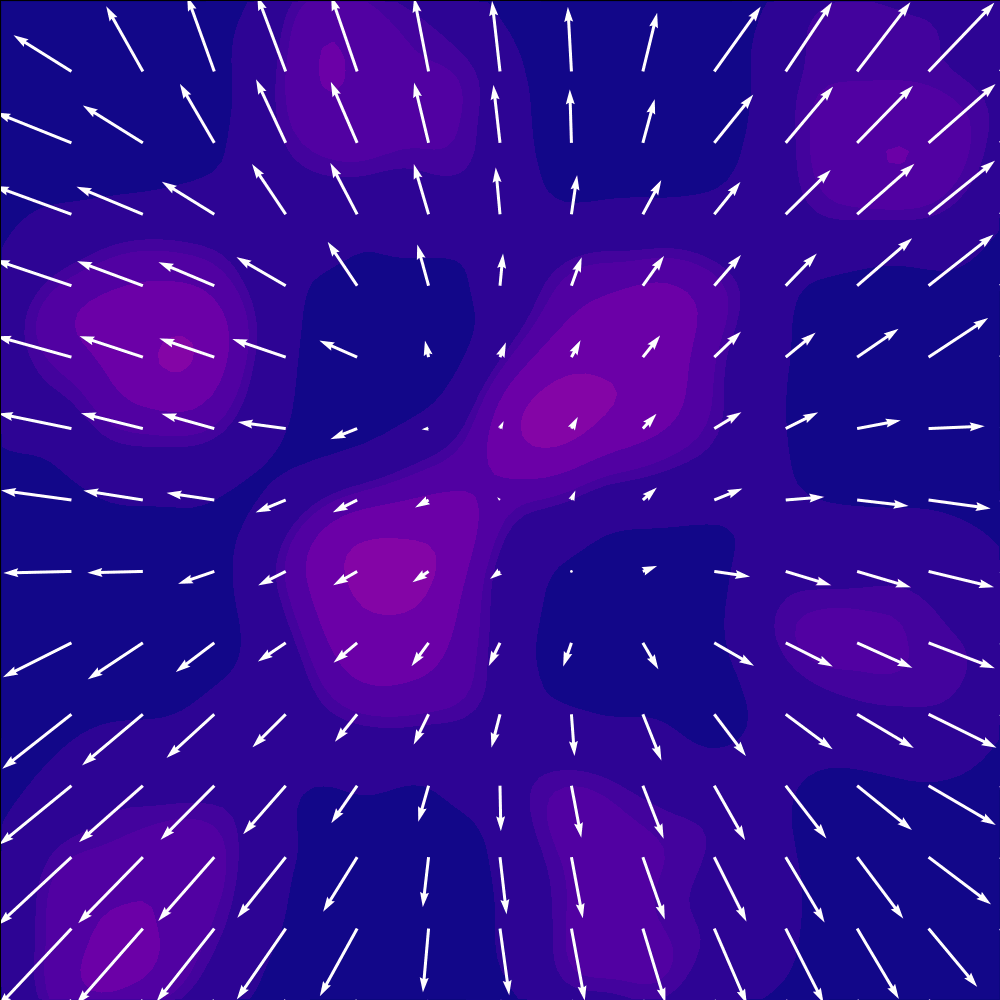
A learned velocity field transporting samples from a Gaussian noise distribution to a target checkerboard distribution over time. Figure from Mark Ogata.
Flow matching sidesteps discretization entirely by learning a velocity field that continuously transports a simple noise distribution into the data distribution. During training, each sample is constructed by linearly interpolating between a noise sample and a data sample at a random time
The velocity field is parameterized by a bidirectional diffusion transformer (DiT) whose inputs are the noisy action trajectory — one continuous vector per timestep, 16 in total. Rather than cross-attending to observations, the network conditions through adaptive layer normalization (AdaLN). The observation and timestep embeddings are summed into a single vector that shifts and scales layer-norm activations at every block.
At inference, the model draws a noise sample and integrates the learned velocity field forward via 100 Euler steps to produce a clean 16-step trajectory, of which only 8 actions are executed. Different starting noise follows different ODE paths and arrives at different modes, giving the policy multimodal coverage without any discrete machinery.
Implementation
Flow matching has become a standard backbone in recent robotic foundation models — π₀ uses it to generate dexterous manipulation trajectories across multiple embodiments. Rather than building from scratch, I started from an open-source DiTFlow implementation designed as a LeRobot plugin policy. It worked almost out of the box after a few changes to adapt it to the latest LeRobot version.
LeRobot’s tutorial for bringing your own policy explains the plugin system in detail. The gist: you package three files as a pip-installable module and register your policy type with LeRobot’s config system.
configuration_ditflow.py— a dataclass that registers the"ditflow"policy type and declares all hyperparameters (horizon length, number of DiT blocks, inference steps, etc.).modeling_ditflow.py— the policy itself: a DiT noise network that predicts velocities, a training step that computes the flow matching loss, and a sampling method that integrates the learned ODE with Euler steps.processor_ditflow.py— pre/post-processing pipelines that normalize observations and unnormalize predicted actions.
Once installed, training uses the same CLI as VQ-BeT:
python -m lerobot.scripts.lerobot_train \
--dataset.repo_id=lerobot/pusht \
--policy.type=ditflow \Paradigm 3: Tokenize It — ARBeT
Theory

A line segment rasterized into adjacent grid cells via Bresenham’s algorithm, then encoded as a sequence of directional tokens. This is the core operation behind ARBeT’s tokenization. Figure from ScribeTokens.
ARBeT borrows its tokenization from ScribeTokens, which encodes trajectories as directional steps rather than coordinate values. Each action trajectory is first rasterized onto a discrete grid via Bresenham’s line algorithm to produce consecutive pixel positions, then each pixel-to-pixel transition is encoded as one of eight compass-direction tokens (N, NE, E, …). BPE compression merges frequent direction subsequences into higher-level motion tokens, shrinking sequence length while preserving decodability.
The prediction model is a causal transformer conditioned on observations via adaptive layer normalization, as in DiTFlow. At inference, the model autoregressively samples eight tokens from a BOS token at temperature 0.7 (best in a sweep), then executes the halfway and final decoded positions as waypoints to produce fine-grained actions without excessive jitter.
I tried conditioning on past actions as well, but the model learned to extrapolate trajectories from action history alone. Randomly dropping the action context during training partially fixed this but still underperformed conditioning on the current observation only. This is one way tokenized actions diverge from tokenized language: past tokens can become a shortcut that bypasses perception.
Implementation
ARBeT follows the same LeRobot plugin structure as DiTFlow — configuration_arbet.py, modeling_arbet.py, processor_arbet.py — but requires a custom dataset that tokenizes the agent’s future actions, truncates or pads them to a fixed length of 32 tokens, and masks padding positions from the loss. Actions are tokenized relative to the agent’s current position rather than the previous command destination, which drifts under control lag.
LeRobot’s training pipeline doesn’t natively support bringing your own dataset. To bridge this gap, a separate training entrypoint monkey-patches make_dataset to inject the tokenized dataset before calling the standard training loop.
python scripts/train_arbet.py \
--dataset.repo_id=lerobot/pusht \
--policy.type=arbetResults
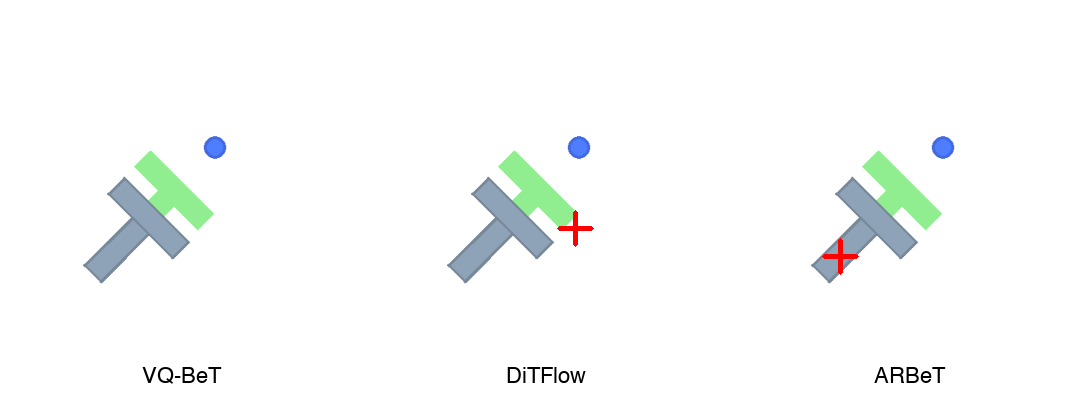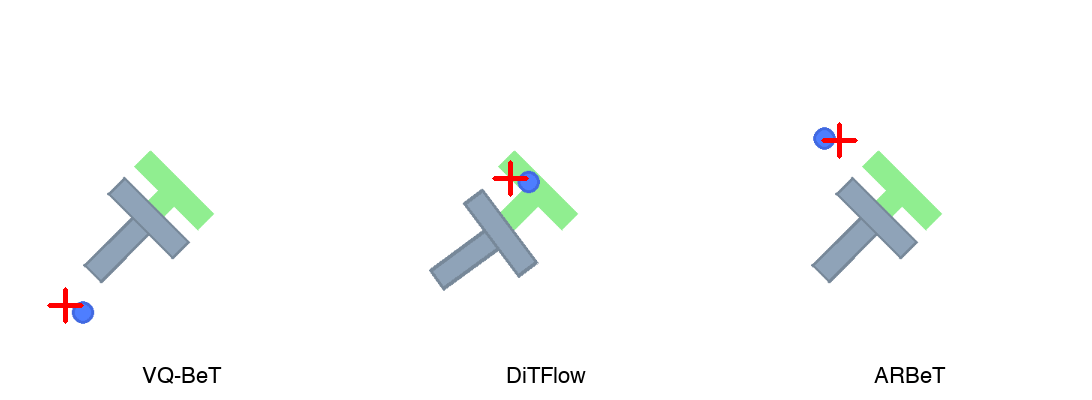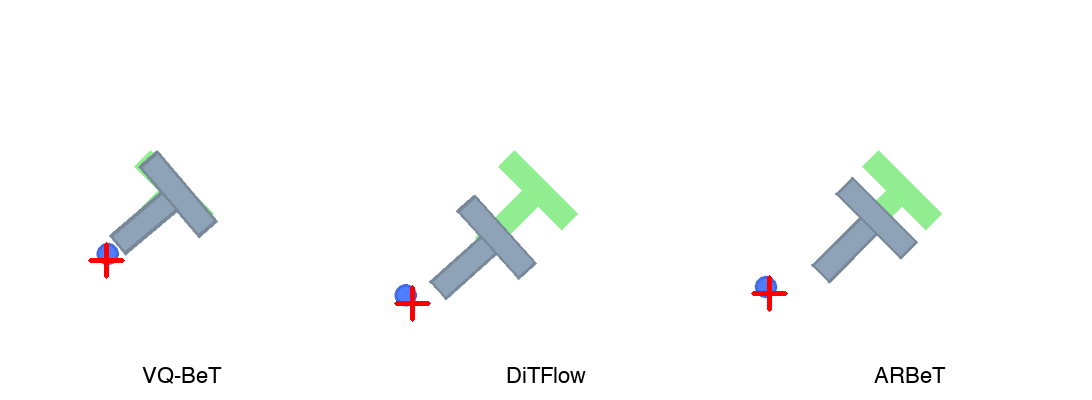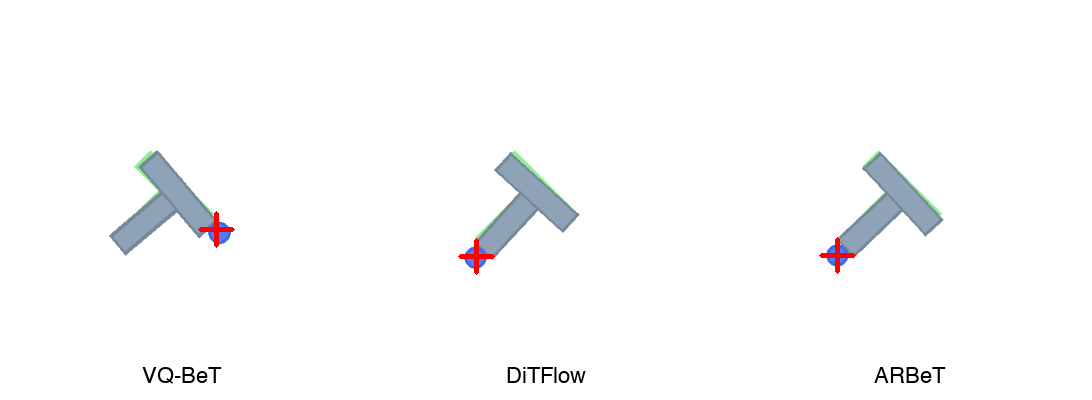
Each policy was evaluated over 50 episodes at its best checkpoint (selected by max reward).
| Policy | Best Step | Max Reward | Success Rate |
|---|---|---|---|
| DiTFlow | 200,000 | 0.8845 | 46.0% |
| VQ-BeT | 50,000 | 0.8489 | 58.0% |
| ARBeT | 75,000 | 0.8040 | 42.0% |
DiTFlow achieves the highest max reward — a measure of how close the T-block gets to the target at any point during the episode — but takes 200k steps to get there. VQ-BeT reaches a comparable level in just 50k steps and leads in success rate at 58%, suggesting its discrete codebook captures actionable modes more sample-efficiently. ARBeT trails on both metrics, but does so with a quarter of the parameters and no task-specific discretization machinery.
Stripping out the shared ResNet encoder, the prediction heads tell a different story on model size: ARBeT’s transformer is 9.5M parameters, compared to DiTFlow’s 42M velocity network and VQ-BeT’s 26M policy network. This wasn’t a deliberate design choice — larger ARBeT models overfit quickly. Next-token prediction over a discrete motion vocabulary is easy for transformers to learn, which lets a small model reach competitive performance — but that same learnability means it quickly exhausts what a small dataset can teach, and scaling up would likely require more data or stronger regularization.
Conclusion
Discrete codebooks, flow matching, and directional tokenization each solve the multimodality problem differently. All three are competitive on Push-T. ARBeT is the first application of interpretable directional tokens to a robotic manipulation task. The 8-direction compass worked for 2D Push-T, but higher-DOF tasks will need richer vocabularies — 3D chain codes are an obvious extension.
What surprised me most was how prone tokenized actions are to overfitting. In language modeling, conditioning on past tokens is essential. Here it became a shortcut that let the model extrapolate trajectories from action history alone, bypassing perception entirely. Next-token prediction over a motion vocabulary is also so learnable that ARBeT’s transformer, a quarter the size of VQ-BeT’s, quickly exhausted what the dataset could teach. Scaling to harder tasks and larger datasets is the clear next step — the same learnability that caused overfitting here could become a strength when there is enough data to demand it.